Project Scope
Currently, advertisers/posters manually label their posts as lost or found which is an additional step
that takes time. In addition to this, it’s not required that advertisers/posters label their post as lost or found,
so the current sort by functionality doesn’t encompass all the posts.
By having the ad be automatically labeled as lost or found, it helps the advertisers to save time and ensures all posts are accurately labeled.
As users looking within this section are clearly visiting this site with the clear intention of either viewing the site in terms of “lost” or “found”,
we identified this as a problem that we could solve.
Not only would this greatly improve the advertising experience, but also would improve the user-experience as well.
This subsection improvement is a win-win that benefits all parties once the improvement has been implemented.
Abstract
Provide users with the ability to search for all ads via lost or found
Provide users with quick links to specific posts based on the most popular topics
Identify images based on keyword
Data Analysis
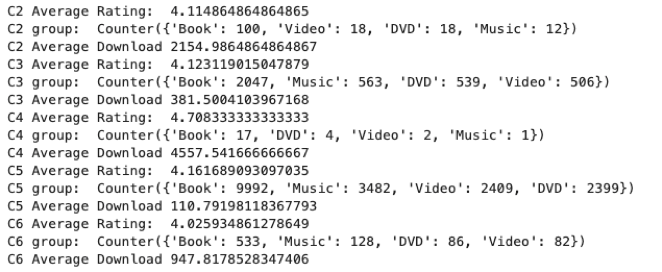
Web Scrapping: Before starting the model construction, we scrapped around 1,000 Lost and Found postings from Craigslist, including 490 postings in the West Lafayette area and 595 postings in Los Angeles, to ensure that enough data acquired for the model training.
TFIDF Vectorizing: We tokenized and normalized them with the Lemmatize function, where we used a pre-defined database to lookup lemma and removed punctuations or filtered out all special characters.
Then we did TD-IDF conversion to weight our terms. Since we would like to drop less important words to reduce the dimension, we set the minimum document frequency equal to 5, which removed all the words with frequency less than 5. In addition to this, we also wanted to keep order information, so we included bag of 2-grams in our argument.
Model Analysis: Our objective is to train a model to automatically label the post into “lost” or “found” category, so it will be a classification problem.
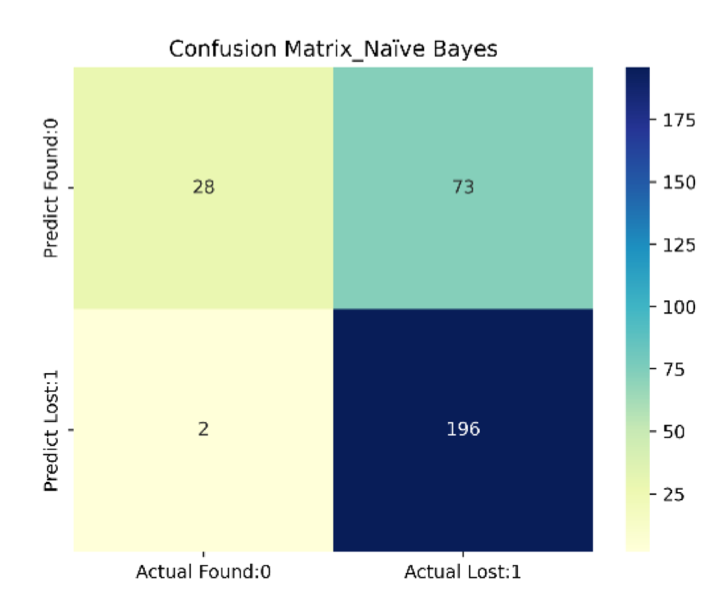
We tried Naïve Bayes, Decision Tree, Random Forest and SVM, four models to do the classification.
Model Performance:


Topic Model: we removed words like “found”, "missing", "lost" “contact", "please", "info", "show" and "home" as these are words related to our posting topics that we already know and don’t need to categorize.
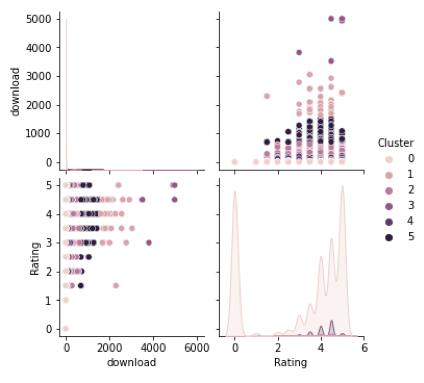
In 3 topic models, we listed top 5 keyword and found that dog and cat appear across our models, meaning that they are the most possible focus in posts.
Top key word:

Image Recognition: Because we saw the words “dog” and “cat” consistently across our top topics, we realized this is due to people not categorizing on specific breeds or detail.
Therefore, if we can recognize the breed, color, or other characteristics, we can create the tags automatically.
This enables website users to investigate all the related posts easily and timely when looking for dogs or cats.
For example, we used image recognition on “dog” and “cat” from images to further identify the image.
Result of Image Recognition:

Conclusion
We wholeheartedly believe that this project and model improves user-experience and brings value both to the user and to Craigslist.
We not only considered what best benefits the user and Craigslist respectively, but also researched and understood the user behavior to best optimize value within the “lost+found” page.
By increasing the amount of efficient and accurate posts, this then increasing the credibility, which could in turn increase the number of users.
With an increased number of users, Craigslist will be able to have an increase in advertisers, which would increase the amount of revenue for Craigslist.